High Availability & Redundancy Design for Enterprise Networks
What High Availability & Redundancy Mean
In enterprise environments, high availability and redundancy design ensure that critical network services remain operational during failures, maintenance, or unexpected disruptions. Proper architectures eliminate single points of failure and support continuous business operations.
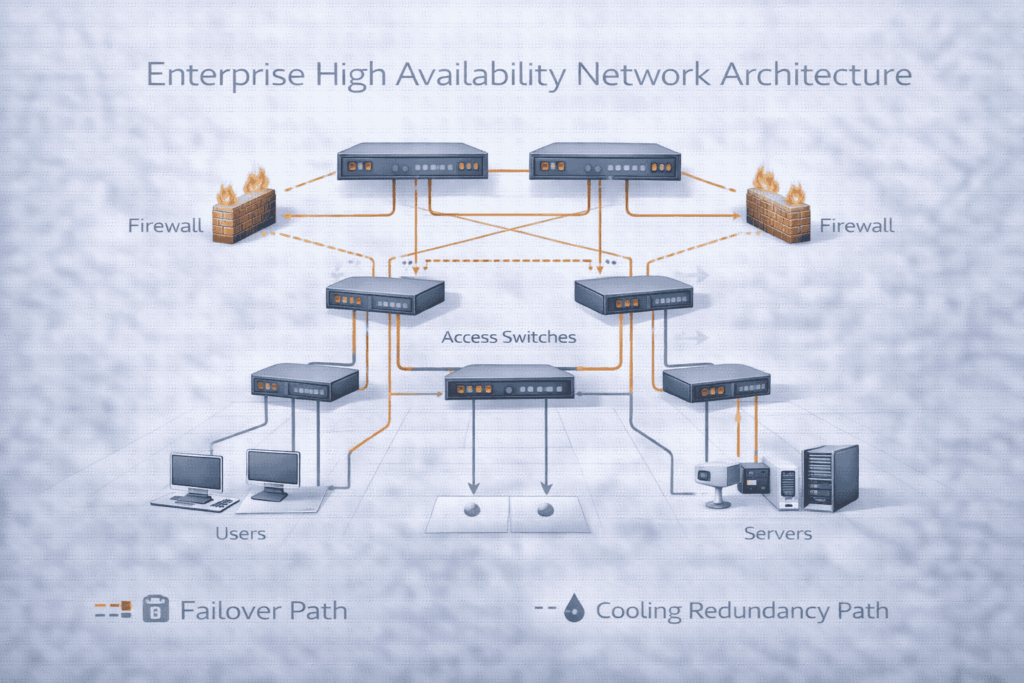
When Your Organization Needs High Availability Design
Investing in a professional HA design is not a luxury—it’s a business imperative in these scenarios:
Mission-Critical Operations with Strict Uptime Requirements: For financial trading, healthcare systems, or e-commerce platforms where every second of downtime has a direct monetary impact.
Complex Multi-Site or Campus Environments: Where the failure of one network node must not cascade to disrupt connectivity across multiple buildings or locations.
Frequent Unexplained Outages or Performance Degradation: A pattern of instability is often the symptom of unaddressed single points of failure requiring a structural redesign.
Binding Compliance or Service-Level Commitments: When you have contractual SLAs or must adhere to regulatory standards that mandate specific uptime percentages and recovery objectives.
Planned Infrastructure Upgrades Without Business Disruption: The need to perform maintenance, patches, or hardware refreshes during business hours without causing an outage.
Proactive Business Continuity and Disaster Preparedness: As a core component of a broader strategy to ensure operational resilience against both technical and physical disruptions.
Common Availability & Redundancy Mistakes We See
Many organizations invest in redundancy but still experience avoidable downtime due to these critical oversights:
Single Points of Failure at Core or Edge: Relying on one core switch, firewall, or internet router makes your entire network vulnerable to a single hardware fault.
Redundancy Only at the Internet Link Level: While dual ISPs are good, neglecting redundancy for internal routing, power, or critical services still leaves the network fragile.
No Regular Failover Testing or Validation: Assuming redundancy works without scheduled testing is a major risk; untested failover mechanisms often fail when needed most.
Asymmetric or Unbalanced Designs: Deploying redundancy in a way where secondary paths are underpowered or misconfigured, causing applications to fail even during a controlled cutover.
Reactive Redundancy Added After Outages: Bolting on redundant components after a major incident leads to complex, poorly integrated, and less reliable architectures.
These gaps systematically lead to avoidable, business-impacting downtime.
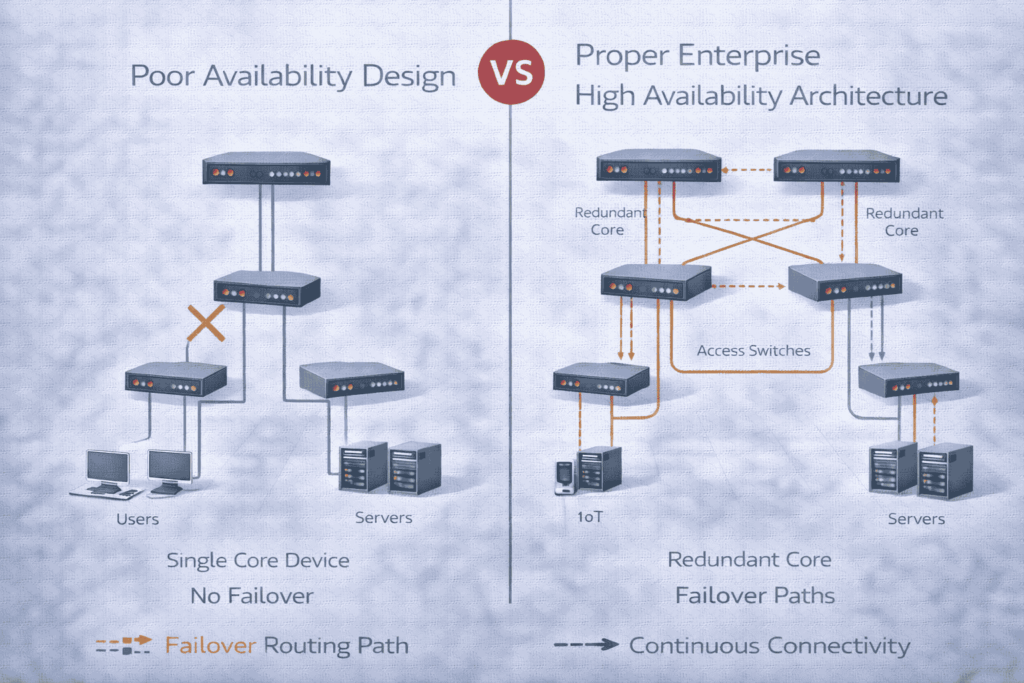
HLIT’s Resilience-First Engineering Approach
We engineer availability into the foundation of your network through a meticulous, layered methodology:
Identification of Single Points of Failure: We conduct a thorough analysis of your entire data path, from power and cooling to network links and software, to catalog every vulnerability.
Hierarchical Redundancy Design: We implement fault tolerance at the core, distribution, and access layers using technologies like MLAG, stackable switches, and redundant supervisors.
Strategic Active/Active vs. Active/Passive Selection: We design the appropriate failover model for each system—whether load-balancing across two active firewalls or using a standby core router—based on performance and cost requirements.
Comprehensive WAN and Internet Link Redundancy: We architect diverse, multi-carrier WAN connectivity with dynamic failover using BGP or SD-WAN, ensuring continuous site-to-site and cloud access.
Rigorous Failover Path Validation and Documentation: We don’t just design it; we test it. We document every failover procedure and expected behavior, creating reliable runbooks for your team.
Maintenance-Friendly Architecture: We design systems that allow for the incremental upgrade or replacement of any component without taking services offline.
At HLIT, high availability is systematically engineered, not optimistically assumed.
Integration with Enterprise Continuity & IT Systems
True resilience requires alignment across your entire technology stack:
Data Centers and Server Platforms: Ensuring network HA designs complement server clustering, storage replication, and virtual machine live migration.
Cybersecurity and Firewall Clusters: Designing network paths to integrate with active/passive or active/active firewall pairs without creating asymmetric routing issues.
Secure Wired and Wireless Networks: Extending redundancy principles to wireless LAN controllers and access layer switching to maintain secure connectivity.
Cloud and Hybrid Connectivity: Implementing resilient, multi-path connections to IaaS and SaaS platforms (e.g., AWS, Azure, Microsoft 365) to treat the cloud as a secure extension of your HA network.
Monitoring and Alerting Systems: Integrating with tools that provide real-time visibility into the health of all redundant components and automatic failover events.
Effective availability strategies must be coherent and operational across all infrastructure layers.
Availability, Scalability & Operational Considerations
Our designs are built to deliver and sustain resilience:
Proven Device and Link Redundancy Strategies: Implementing protocol-based failover (e.g., HSRP, VRRP, OSPF) that is predictable and fast, typically sub-second.
Intelligent Load Balancing and Traffic Distribution: Utilizing technologies like ECMP (Equal-Cost Multi-Pathing) to use all available bandwidth and redundant paths actively.
Structured Maintenance Without Disruption: Creating clear procedures for performing hardware and software updates within predefined maintenance windows without impacting users.
Growth Planning Without Re-architecture: Designing modular capacity so new sites, users, or applications can be added without compromising the existing redundancy model.
Comprehensive Operational Visibility and Monitoring: Implementing dashboards and alerts that provide a clear view of primary/secondary system status and historical failover events.
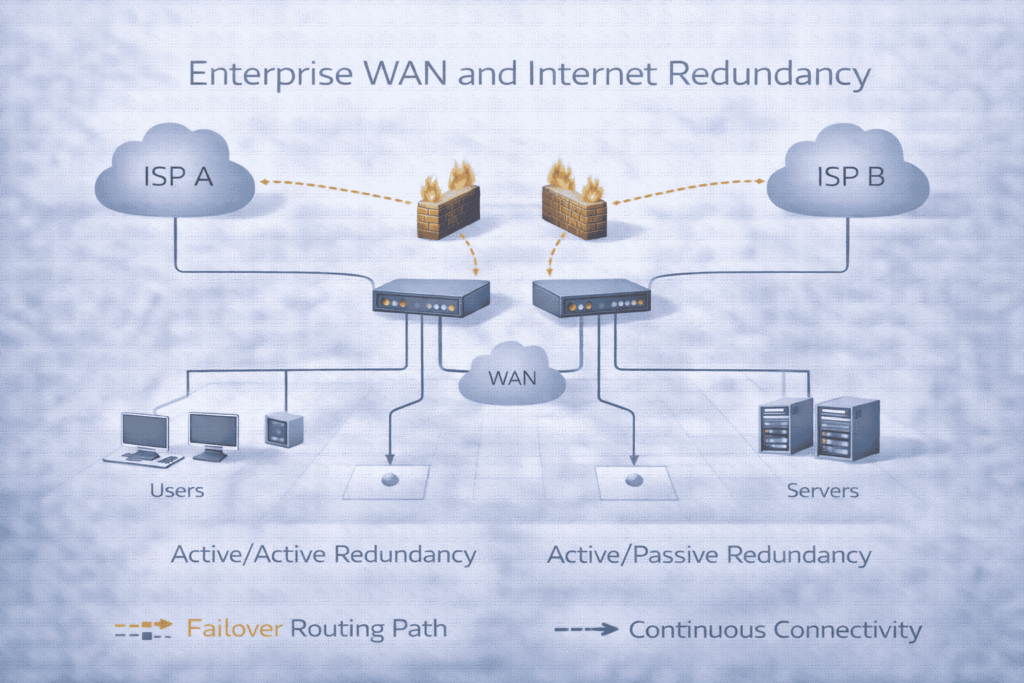
FAQs
What is high availability in enterprise networks?
High Availability (HA) refers to a design philosophy and set of technologies that minimize network downtime by eliminating single points of failure. The goal is to achieve “five-nines” (99.999%) uptime or better, which translates to less than 5 minutes of unplanned outage per year. It’s achieved through redundant hardware, diverse pathways, and automated failover processes that keep applications running seamlessly during a component failure or maintenance event.
How do you design true network redundancy?
We design redundancy in layers: Physical Redundancy (dual power supplies, diverse fiber routes), Device Redundancy (paired core switches, clustered firewalls), and Path Redundancy (multiple internet links, dynamic routing protocols). Crucially, these layers are integrated and tested. The design must also include Logical Redundancy using protocols like VRRP or MLAG that make two devices appear as one to the network, enabling automatic and seamless failover without manual intervention.
What is the difference between redundancy and backup?
Redundancy is about continuous operation. It involves live, parallel systems that instantly take over when a failure occurs—there is no service interruption. Backup is about data recovery. It involves taking periodic copies of data that can be restored after a failure has occurred, which involves downtime. A resilient business requires both: redundancy to prevent outages, and backups to recover from catastrophic data loss or corruption.
How do automatic failover mechanisms actually work?
Failover mechanisms use “heartbeat” signals or health checks between redundant devices. For example, two core switches in a pair constantly communicate. If the primary switch stops sending heartbeats (due to a fault), the secondary switch detects the failure within milliseconds. It then automatically assumes the primary role, taking over the IP addresses and forwarding traffic, often before users notice a problem. This process is governed by pre-configured protocols and requires symmetric design to work reliably.
What are the most common causes of downtime in "redundant" networks?
Paradoxically, downtime often occurs in networks that have redundancy but suffer from: 1) Configuration Drift, where the primary and secondary devices have mismatched settings causing failover to break; 2) Untested Failover, where assumed redundancy fails in a real event due to an undiscovered bug or error; 3) Common-Mode Failures, where a single event (like a power grid issue or faulty software patch) takes down both the primary and backup systems simultaneously; and 4) Human Error, such as a mistaken configuration change applied to only one device in a pair. This is why disciplined design, consistent automation, and regular testing are non-negotiable.
Design Networks That Stay Online
If uptime matters to your business, HLIT delivers high availability and redundancy architectures designed to keep enterprise networks operational—during failures, upgrades, and growth.
